En el artículo Graylog – Arquitectura tolerante a fallos y escalable{.row-title.anti-aede-checked} explicaba la arquitectura que usamos en Genexies Mobile{.anti-aede-checked} para el sistema de gestión de logs de nuestros servicios. No es sólo un sumidero centralizado de logs, si no que estamos definiendo un sistema para controlar la calidad de nuestros servicios directamente desde el comportamiento del código fuente.
graylog almacena en un cluster de elastic todas las trazas, que además de incluir la información propia de las trazas “planas” a las que estamos acostumbrados en software (marca de hora, clase o fichero que genera la traza, nivel de traza, mensaje), permite almacenar informacion estructurada adicional: ids de sesión, ids de transacciones, cabeceras (User-Agent y otras propias del entorno web), componente de la arquitectura (porque tenemos varios enviando trazas), etc.
El resultado es un almacén estructurado de varios teras de tamaño (gestionado impecablemente por los propios clusteres de elastic y graylog).
El problema
Como he dicho, tenemos varios componentes de la arquitectura enviando trazas al sistema, todos ellos usando su propio “logger” (PHP, JAVA, JavaScript) pero siempre haciéndolo a través del sistema de colas RabbitMQ.
En el artículo enlazado al principio explico los motivos de la arquitectura de graylog escogida, y si bien esta nos permite afrontar mejor los posibles mantenimientos y el crecimiento del sistema, no ha evitado los problemas que tenemos de saturación en la recepción de tal volumen de trazas.
El sistema de colas RabbitMQ amortigua parte del problema, pero se acaba saturando también.
El problema concreto es el siguiente:
- Existen picos de concurrencia en el uso de nuestros servicios, donde se suman las visitas a los portales con procesos internos que debemos ejecutar prácticamente 24×7.
- Estos picos de uso de los servicios implican un pico en la generación de trazas.
- La raíz del problema: la capacidad de procesado y almacenado de las trazas es limitada y parece no poder crecer como el resto del sistema de graylog que tenemos.
- Primer efecto en el sistema de colas: producción > consumo.
- RabbitMQ comienza a sufrir los efectos: mayor consumo de memoria de la cola, comienza a paginar a disco, reduce su rendimiento, empieza a ralentizar la producción de trazas, esto hace que se agolpen los clientes (productores), comienza a subir el número de descriptores de ficheros en uso (debido a los sockets de los clientes esperando a que les atiendan), aumenta el uso de memoria debido a la gestión de cada cliente conectado…
- Y entonces RabbitMQ activa su medida de protección de disponibilidad: cambia la cola al estado “flow”, que básicamente significa: limitar la tasa de producción de datos en la cola, y de hecho denegar nuevas conexiones de clientes.
- Los clientes se ralentizan al no poder producir las trazas al ritmo necesario.
- Los servicios se ven afectados.
La solución
Sin abordar el que parece ser el origen del problema, esto es, la capacidad y el rendimiento del almacén de datos (cluster de elastic), tenemos como objetivos:
- Poder tener el sistema activo para todos, o al menos, los componentes de la arquitectura más importantes. Tenemos ciertos componentes software relacionados con partes del negocio más críticas: no pueden fallar pero queremos tenerlos monitorizados con este sistema.
- Aislar los componentes de forma que la saturación en algunos de ellos no afecte al resto.
El segundo punto se debe a que usaremos el mismo sistema graylog para todos los servicios, pero aun así, queremos que se haga un tratamiento aislado de ellos.
Al ser una mejora de la plataforma de Genexies Mobile, de hecho hace un año no sabíamos ni que existía graylog, la estrategia para implantar el sistema ha sido la siguiente: ir servicio por servicio adaptándolo y activando el envío de trazas de producción.
La solución encaja con ese modelo y permite ir añadiendo servicios sin afectar a los ya integrados. Al menos esto es lo que queremos conseguir.
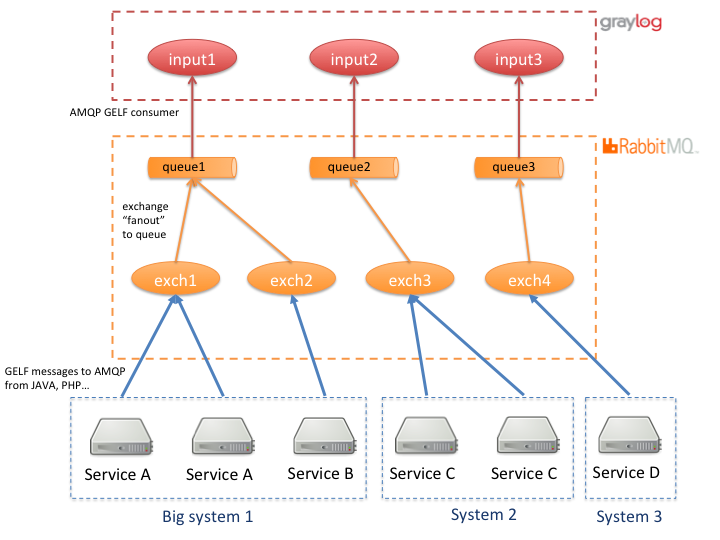 {.anti-aede-checked}<figcaption class="wp-caption-text">RabbitMQ exchanges and queues + graylog inputs configuration for minimum data loosing</figcaption></figure>
{.anti-aede-checked}<figcaption class="wp-caption-text">RabbitMQ exchanges and queues + graylog inputs configuration for minimum data loosing</figcaption></figure>
La implementación
RabbitMQ separa internamente la producción y el consumo de mensajes: la producción se hace hacia “exchanges”, el consumo desde “queues” y permite definir rutas entre ambos.
Esta separación permite que en nuestro caso segmentemos las trazas de distintos servicios de forma que compartan o no cola entre ellos, en función de nuestras necesidades.
Así, los servicios que sabemos que originan la saturación podemos aislarlos en colas independientes, dejando así intacto el procesamiento de trazas de otros servicios que no se saturan, pero que son más importantes de monitorizar.
Conclusiones
En las primeras pruebas hemos visto como el sistema parece comportarse mejor con este esquema donde hay varias colas y dirigimos las trazas a unas u otras en función de la agrupación. No sólo no se saturan los servicios importantes, si no que además parece que RabbitMQ esté optimizado para trabjar con gran cantidad de colas más que con una sóla cola con muchos datos, algo que no es descabellado.
Quizá estés pensando que el problema lo podríamos haber solucionado dando más capacidad al cluster de Elastic, que parece el cuello de botella, pero creo que en este sentido, con los recursos que tenemos actualmente, ese cuello de botella va a seguir y lo que necesitamos es poder amortiguar los picos, algo que precisamente se puede hacer con el sistema de colas RabbitMQ que tenemos en la arquitectura de Graylog que usamos.
Sobre el propio RabbitMQ, nos ha gustado tanto la sencillez con la que se puede implementar un sistema de colas, la facilidad con la que se puede hacer crecer un cluster de varios servidores, los modos de federación que dispone, la configuración… que estamos empezando a implantarlo en otras partes de la arquitectura de Genexies.
Iré contando…